
建構服務,除了服務本身要可以為使用者帶來價值、快速因應市場的需要,服務的可靠性也是一個很重要的變數。
不穩定的服務,常常會逼的使用者失去耐心,在一次又一次的服務中斷、資料遺失後,使用者很快會漸漸對你所維護的服務失去信任,出走去尋找其他更穩定又可以符合他需求的選擇。
作為接案公司,大多數的案子都不是從頭開始、許多都是幾經轉手到我們手上。除了軟體服務開發外,服務的維運也是我們的日常工作之一。
一般來說,當情況允許時,我們會傾向導入 Error Tracking 以及各式的 Performance Monitoring 服務來協助我們衡量服務的穩定性,以及找到需要進一步改進的瓶頸。
Why Puma
Rails 5.0 開始,為了加入對 Websocket 的支援 (Actioncable),開發預設的 HTTP Server 從 WEBrick 被換成了 Puma。
除了 Puma 以外,另一個比較知名的選擇是 Phusion Passenger,究竟是 Puma 好、還是 Passenger 穩定,孰優孰劣一直是個沒有終點的論戰,即便在我們公司內的開發者們或許也很難達成一致認同的結論(笑)。
隨便一查,網路上關於這個爭論的相關文章文章眾多,甚至 Phusion Passenger 也針對自己與 Puma 的論戰,在自己的 Wiki 中發表了一篇 Puma-vs-Phusion-Passenger。雖然因為 Phusion Passenger 是個商業公司的產品、可以想見這篇文章有一定程度的歧見,但其中有些比較、與論點還是滿值得一讀。
一般來說,我選擇 Puma 而不是 Phusion Passenger 的原因在於:
- Puma 是個免費而且開源的專案,Passenger 則是商業產品,同時推出開源、與企業版本,想當然爾 Passenger 在開源(免費)版本中有一定的限制,好吸引客戶去購買企業版本。
- Puma 預設有對 Multi-Threaded、Clustered Mode (Multi-Workers) 的支援、Passenger 在免費版本中則僅支援 Multi-Process、Single-Threaded。普遍上的認知以及經驗法則一般告訴我們,支援 Multi-Threading 一般會有比較低的 Memory usage,在 Concurrency 的表現也相較 Multi-Process、Single-Threaded 要來的好一點。而 Passenger 的 Multi-Threaded 僅在企業版中有支援。
- 一般來說選擇 Phusion Passenger 企業版、支付高額的授權費用對我們的客戶並沒有什麼決定性的優勢
加上我們使用 Puma 作為 Rails Server 也有些時日,對於他的調效以及維護上也有一定的經驗,即便面對每日數以百萬、千萬的請求,也並沒有發生過什麼嚴重的問題,因此在客戶沒有強烈偏好的情況之下我大部分會以 Puma 作為我們的 Rails Server 方案。
為什麼使用者會遇到 503 Service Unavailable
在某個專案中,我們偶爾會監測到伺服器在某個短暫的期間會返回 503 Service Unavailable 的 Response Code,在 AWS 的 Load Balancer 中會被判定為 Unhealthy Host,所有的請求會被轉送到其他被視為 Healthy 的 Server 上。
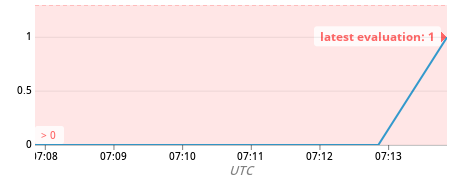
AWS Load Balancer 回報在該時間內 Unhealthy Host Count 為 1
運氣不好的使用者,會在這期間遭遇短暫的服務中止現象。雖然狀況會在相當短暫的時間自動排除,但就如開頭所述,服務的中斷很容易就會讓使用者失去耐心,在以提供即時資訊給使用者為主要目標的網站上更是不被允許的狀況,為了提升服務可靠性,我們開始逐一排查所有的可能。
比對了紀錄後,我們發現該狀況的發生時間,大致都與我們發布新版本程式到生產環境的時間相符,在進一步的測試與觀測之後,很快就發現了在發布流程中,進行到 Puma 重啟步驟的時候會造成這個現象。
要理解為什麼 Puma 重啟的時候會發生這個現象,我們首先要理解 Puma 重啟的過程以及不同的重啟類型。
Puma 的重啟模式
Puma 的重啟模式分成三種,就跟斯斯有三種一樣(爛哏)。
Normal Restart
Puma 的 Normal Restart 就如同字面一樣,並沒有什麼特別的,也是上述例子中採用的重啟方式。為了方便理解,可以把它想像為重開你的電腦,重開步驟開始到完成這段期間,無法接受新的 Requests,這也是為什麼在 Puma 重啟時會造成短暫的 503 Service Unavailable 的原因。
觸發 Puma Normal Restart 的方式,是對 puma process 送出 SIGUSR2 的 Kill Signal。
Hot Restart
Hot Restart 透過設定額外的 Server Socket,來確保在 Puma 重啟的過程中,可以持續的接收請求,並佇列等待處理。直到 Puma server 重啟完成後,再將佇列中的請求處理並返回。
這個方式乍看之下挺完美,不會像 Normal Restart 那樣造成短暫的 503 Service Unavailable,但是在完成重啟的程序前 Reuqests 只會進到佇列,並不會被處理,因此在重啟的過程中 Requests 會較慢返回。
Zero Downtime 好像勉強算是做到了,但如果想要做到 Zero Downtime 又 Zero Hanging 的版本發布該怎麼辦呢?
Phased-Restart to the rescue
Phased-Restart 又被稱為 Rolling Restart。同樣如同他的名字般,當進行 Phased-Restart 時,Puma 會一個、一個的把 Worker 殺掉重啟,在 Worker 重啟的過程中,其他運作中的 Worker 可以繼續接受並回應使用者的需求,透過這樣的方式可以達成 Zero Downtime 且 Zero Hanging 的版本發布。除此之外,多個 Workers 也能讓你更有效率的運用系統資源去並發處理請求。
由於這個重啟模式僅在有多個 Workers 的時候才有作用,因此這個模式只在 Clustered Mode 的模式下生效。
另外需要特別注意的是,由於這個重啟模式是逐一更新各個 Workers,因此在 Workers 更新的時候,新舊版本的程式碼會有機會共存。在這個前提下,必須要考慮新版本與就版本程式的「向下相容性」(Backwards-compatibility),以避免例外狀況的發生。這個情況尤其常發生在 Database Migration 變動了原有的資料表時,例如:Drop 掉了原有的欄位,如果某個 Release 對原有的 Database 結構進行了大量非向下相容的更新的話,必須評估這短暫的不一致造成的例外狀況是不是可接受的風險,也許此時使用 Normal Restart 或是 Hot Restart 會是更保守的方式。
另外在 Phased-Restart 的時候,Configuration File 也不會被重新讀取,所以當 Configuration File 更新的時候,一樣必需借助 Normal Restart 或是 Hot Restart 來重啟服務。
這邊需要額外一提的是,由於 JVM 與 Windows 不支援 processes ,如果你使用的是這兩者其一作為你的生產環境,那麼你無法使用 Clustered Mode,這時候 Fallback 回去使用 Hot Restart 並借助 Thread 達到更好的 Concurrency。
觸發 Puma Normal Restart 的方式,是對 puma process 送出 SIGUSR1 的 Kill Signal。
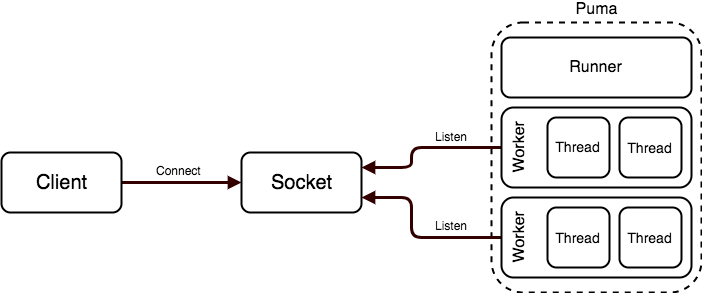
Puma 的常見架構。摘自 Puma 官方文件:Architecture。
來動手吧
更新 Puma Config
我們所維護的專案大部分都是以 Ruby on Rails 框架作為基礎架構,在 Rails 5.0 後的版本,專案被初始化時預設就會在 config/puma.rb 中產生一個 Puma 的初始設定檔。依照需求,可以直接編輯並使用這個設定檔,或是按照實際需要搭配其他的自動化部署工具,在不同的環境下給予不同的設定,這邊我們直接使用一般置放在專案目錄下的 config/puma.rb 作為示範。
Enable Worker Mode
據上一段落所述,為了達到 Zero Downtime 與 Zero Hanging 的版本部署,我們希望在大多情況下版本更新後,以 Phased-Restart 作為預設的重啟方式,因此我們需要先允許 Clustered Mode (Multi-Workers) 開啟。一般來說,Workers 的數量與所部署伺服器的 CPU Cores 數量一致會有最好的效果。
在 config/puma.rb 加入以下設定:
workers Integer(ENV['WEB_CONCURRENCY'] || 2)
在 Clustered Mode 底下,每個 Worker 之間彼此獨立,因此 Thread-Safe 並非是必要條件,但是如果你的程式碼可以達成 Thread-Safe,一般來說啟用 Puma 的 Internal Thread Pool 可以借助 Threading 在消耗較少記憶體的方式提高 Throughput 以回應請求。因此我們也將啟用 Puma 的 Interal Thread Pool。
Enable Puma Internal Thread Pool
上一章節附圖《Puma 的常見架構》圖中,我們可以看到每個 Worker 會有自己的 Thread Pool,透過啟用 Puma Internal Thread Pool 可以更有效率的運用系統資源達到更好的並發處理效果。
在 config/puma.rb 加入以下設定:
threads_count = Integer(ENV['RAILS_MAX_THREADS'] || 5)
threads threads_count, threads_count
上例 threads後所接的第一個參數是每個 Workers 的最小 threads_count,第二個參數是每個 Workers 的最大 threads_count,一般來說我自身的習慣是從 5, 5 起跳,再依據效能表現決定是否上調這個設定。這邊可以依照自己的需求小心的將設定值調整以最好的利用伺服器資源。
Preload App
在前一個章節中提過,在某些情況下你還是需要借助 Normal Restart 或是 Hot Restart 來重啟你的伺服器。這種時刻我們會希望可以盡可能的縮短 Downtime 或是 Request Hanging 的時間、加速 Workers 被重啟完畢所需要的時間,此時可以在 Puma 設定檔中加入 preload_app! 的設定,他這告訴 Puma 在 Worker Forking 之前預先載入你的 Code,降低在整個步驟中的記憶體消耗並加快速度。
在 config/puma.rb 中加入
preload_app!
啟用 preload_app! 還有一個重要的好處,它讓你可以使用 on_worker_boot Block 定義在 Worker 被準備好,但真的開始接受 Requests 前要先準備好哪些事情。
Prepare Connection Pool on Worker Boot
在 Worker 重啟完重新開始接收使用者請求前,我們會希望先做好某些準備,例如先將 Database 的 Connection Pool 準備好,為了做到這件事情我們可以在 config/puma.rb 加上
on_worker_boot do
ActiveSupport.on_load(:active_record) do
ActiveRecord::Base.establish_connection
end
end
上述的步驟都完成後,應該會有一個接近以下樣子的 Puma 設定檔:
# config/puma.rb
#!/usr/bin/env puma
directory '/app/current' # 替換為自己 Application 的 Working Directory
rackup "/app/current/config.ru"
environment ENV['RAILS_ENV'] || 'development'
workers Integer(ENV['WEB_CONCURRENCY'] || 2)
threads_count = Integer(ENV['RAILS_MAX_THREADS'] || 5)
threads threads_count, threads_count
preload_app!
on_worker_boot do
ActiveSupport.on_load(:active_record) do
ActiveRecord::Base.establish_connection
end
end
Process Monitor
將 Puma 放到伺服器上面執行,我們會希望將 Puma 交給 Process Monitor 管理,好確保 Puma 常保在執行狀態,當系統重開或是 Puma 不幸掛掉時,讓 Process Monitor 來自動重啟 Puma。
過去有些人為了在 Capistrano 部署的過程中維持 Puma 啟動的狀態,會選擇 Daemonizing Puma 或是 Sidekiq 等服務,但不管是 Puma 或是 Sidekiq 都已經強烈建議不要這麼設定,畢竟 Daemonizing 無法有效而且可靠的監控 Child processes,Puma 也不像 Unicorn 需要 Daemonize 就可以做到 Zero Downtime Restart。選用像是 Systemd 的 Process Monitor 可以確保你的 Puma Crash 需要重啟的時候有更好的反應速度。
要使用 Systemd 作為 Puma 的 Process Monitor,以 Amazon Linux 2 系統為例,將以下的 Systemd 設定檔置於 /usr/lib/systemd/system/puma.service
[Unit]
Description=Puma HTTP Server
After=network.target
[Service]
Type=simple
User=app-user
WorkingDirectory=/app/current/
EnvironmentFile=/etc/default/app
ExecStart=/opt/ruby-2.6.2/bin/bundle exec puma -C /app/shared/config/puma.rb
ExecReload=/bin/kill -s SIGUSR1 $MAINPID
ExecRestart=/bin/kill -s SIGUSR2 $MAINPID
Restart=always
[Install]
WantedBy=multi-user.target
你需要自行將上例中的 WorkingDirectory, EnvironmentFile, ExecStart 指令中的各個設定檔、執行位置按照你實際設定的位置調整。
有沒有注意到在 ExecReload 中,我們使用的是 /bin/kill -s SIGUSR1 $MAINPID ,也就是說當執行 systemctl reload puma.servica 時,實際上執行的對應指令是 Puma 的 Phased-Restart;在 ExecRestart 中,我們使用的是 /bin/kill -s SIGUSR2 $MAINPID,也就是說當執行 systemctl restart puma.servica 時,實際上執行的對應指令是 Puma 的 Normal Restart。
另外需要注意給 Systemd 的 EnvironmentFile 所需的格式如下:
RAILS_ENV=production
WEB_CONCURRENCY="2"
ASSET_HOST="https://example.5xruby.tw"
而不是系統 Environment File 所需的 export RAILS_ENV=production 形式。
上述設定完成後,可以透過以下指令在伺服器上面啟用你的 Puma Service,注意你需要具備 Root 權限以執行這些指令
# 對 Puma.service 或是 Systemd 設定檔有變動時需要 Reload 設定
systemctl daemon-reload
# 將 Puma.service Enable,所以當系統重啟時他會自動重啟
systemctl enable puma.service
# 初始話並啟動 Puma.service
systemctl start puma.service
# 檢視 Puma.service 的狀態
systemctl status puma.service
# 使用 Normal Restart 重啟 Puma
systemctl restart puma.service
# 使用 Phased Restart 重啟 Puma
systemctl reload puma.service
在檢視 Puma Service 的狀態時,你應該要看到類似以下資訊:
● puma.service - Puma HTTP Server
Loaded: loaded (/usr/lib/systemd/system/puma.service; enabled; vendor preset: disabled)
Active: active (running) since Sun 2019-07-21 19:44:17 JST; 2s ago
Process: 29874 ExecReload=/bin/kill -s SIGUSR1 $MAINPID (code=exited, status=0/SUCCESS)
Main PID: 21382 (ruby)
CGroup: /system.slice/puma.service
├─21382 puma 3.12.0
├─21385 puma: cluster worker 0: 21382
└─21389 puma: cluster worker 1: 21382
Jul 21 19:44:17 stg-web01 systemd[1]: Starting Puma HTTP Server...
Jul 21 19:44:18 stg-web01 bundle[21382]: * Pruning Bundler environment
Jul 21 19:44:18 stg-web01 bundle[21382]: [21382] Puma starting in cluster mode...
Jul 21 19:44:18 stg-web01 bundle[21382]: [21382] * Version 3.12.0 (ruby 2.6.2), codename: Llamas in Pajamas
Jul 21 19:44:18 stg-web01 bundle[21382]: [21382] * Min threads: 5, max threads: 5
Jul 21 19:44:18 stg-web01 bundle[21382]: [21382] * Environment: staging
Jul 21 19:44:18 stg-web01 bundle[21382]: [21382] * Process workers: 2
Jul 21 19:44:18 stg-web01 bundle[21382]: [21382] * Phased restart available
Jul 21 19:44:18 stg-web01 bundle[21382]: [21382] Use Ctrl-C to stop
Jul 21 19:47:02 stg-web01 systemd[1]: Reloaded Puma HTTP Server.
上面的狀態中,我們可以看到 Puma 以 Clustered Mode 執行,並且以當你使用 systemctl reload puma.service 重啟 Puma 時,應該要可以看到他使用 Phased-Restart 的訊號重啟了 Puma。
所以我說那個說好的 Hot Restart 呢
截至目前為止,我們達成了透過 Process Monitor 來控制 Puma 的 Normal 跟 Phased-Restart 呢,Hot Restart 則需要透過 Socket Activation 來實現。
Hot Restart 的做法是讓 Systemd 先開啟 Puma Socket,綁定 ListenStream 接收請求,Puma Socket 會在 Puma Service 啟動後再將請求轉送過去。如此一來只要 Puma Socket 維持開啟,Puma Server 因為重啟、更新而無法處理請求時,請求仍會被 Puma Socket 接受,等到被重啟完成後的 Puma Server 所接收。
要在 Systemd 中開啟一個 Socket 接收請求,以 Amazon Linux 2 系統為例,將以下的 Systemd 設定檔置於 /usr/lib/systemd/system/puma.socket
[Unit]
Description=Puma HTTP Server Accept Sockets
[Socket]
ListenStream=0.0.0.0:9292
# 若綁定 UNIX Socket,按照實際設定你可能會需要 SocketUser, SocketGroup 等設定
# ListenStream=unix:///app/shared/tmp/sockets/puma.sock
NoDelay=true
ReusePort=true
Backlog=1024
[Install]
WantedBy=sockets.target
注意上述範例中的設定檔,ListenStream 應依照實際綁定的 Socket 設定,如果有指定 Socket 的話(如使用 UNIX Socket), config/puma.rb 中應該也有同樣的設定。
接著在原本 Puma Service 的 Systemd 設定檔 [Unit] 中加入 Socket Activation 的設定,確保 Puma Service 啟動前 Puma Socket 應該先行啟動,改完之後的設定檔應該如下:
[Unit]
Description=Puma HTTP Server
After=network.target
# 增加 Socket Activation 設定,確保 Puma Service 啟用前 Puma Socket 已經打開
Requires=puma.socket
[Service]
Type=simple
User=app-user
WorkingDirectory=/app/current/
EnvironmentFile=/etc/default/app
ExecStart=/opt/ruby-2.6.2/bin/bundle exec puma -C /app/shared/config/puma.rb
ExecReload=/bin/kill -s SIGUSR1 $MAINPID
ExecRestart=/bin/kill -s SIGUSR2 $MAINPID
Restart=always
[Install]
WantedBy=multi-user.target
上述 Systemd 設定檔完成後,讓我們再次透過 Systemd 指令啟用 Socket Activation
# 因為更改了 puma.service, 新增了 puma.socket 的設定,需要執行 daemon-reload
systemctl daemon-reload
# 確保 puma.socket 跟 puma.service 在系統重啟時都能被重啟
systemctl enable puma.socket puma.service
# 啟用 puma.socket 以及 puma.service
systemctl start puma.socket puma.service
# 檢視 puma.socket 以及 puma.service 的狀態
systemctl status puma.socket puma.service
# Puma Socket 持續監聽需求、重啟 Puma Service
systemctl restart puma.service
# 對 Puma 服務進行 Normal Restart,重啟 puma.socket 以及 puma.service
systemctl daemon-reload
systemctl restart puma.socket puma.service
設定完 Puma Socket 後,單獨執行 systemctl restart puma.service 時,由於 Puma Socket 會持續接收請求,所以並不會造成 503S ervice Unavailable 回應,只會有 Request Hanging 的行為。如此一來在一些必須要使用 Hot Restart 的情境下,使用者只會稍稍的感受的 Request 回來的速度較慢、並不會直接的感受到服務中斷。
假如要重啟整個 Puma 相關服務,像是更改綁定的 ListenStream 等,則透過同時重啟 Puma Socket、Puma Service 來達成。
搭配 Puma Socket 達成 Graceful Restart 的方式,不論是在 Puma 的 Single Worker Mode、或是 Clustered Model 中
Integrate with Capistrano
完成了伺服器端的設定,接下來讓我們把 Puma 重啟的步驟跟整個自動化佈署流程整合在一起,一般來說在 Ruby 專案中我們最常使用的自動化部署工具是 Capistrano,這邊以 Capistrano 為例,在專案的 lib/capistrano/tasks 中新增 puma.rake
# frozen_string_literal: true
namespace :puma do
task :start do
on roles(:web) do
within release_path do
execute :sudo, :systemctl, :start, :puma
end
end
end
task 'phased-restart' do
on roles(:web) do
within release_path do
if server_started?
execute :sudo, :systemctl, :reload, :puma
else
invoke 'puma:start'
end
end
end
end
task :restart do
on roles(:web) do
within release_path do
if server_started?
execute :sudo, :systemctl, :restart, :puma
else
invoke 'puma:start'
end
end
end
end
task :status do
on roles(:web) do
within current_path do
if server_started?
execute :sudo, :systemctl, :status, :puma
else
warn 'Puma not running'
end
end
end
end
task :stop do
on roles(:web) do
within release_path do
execute :sudo, :systemctl, :stop, :puma
end
end
end
def server_started?
test :sudo, :systemctl, :status, :puma
end
end
加上以上的設定檔,就可以在 Capistrano Tasks 中透過
cap production puma:status:查看 Puma 的狀態cap production puma:start:啟動 Pumacap production puma:phased-restart:Phased-Restart Pumacap production puma:restart:Hot Restart Puma
等指令來控制 Puma。
一般來說,由於 Phased-Restart 可以同時達到 Zero Downtime 以及 Zero Hanging 的版本部署,我們會希望他是程式碼更新後,預設的 Server 重啟方式,可以在 config/deploy.rb 的最後加入以下設定,讓 Capistrano 在部署結束後自動以 Phased-Restart 模式重啟 Puma。
after 'deploy:published', 'puma:phased-restart'
小結
初期在設定 Puma 與 Capistrano 的整合時,我們常會倚賴一些 Gem 來幫我們快速方便的達成目標,當 Puma 變成 Rails 預設的 Web Server 時,我們很容易就會將所有的一切視為理所當然。
此例中,為了追求所謂 Zero Downtime、Zero Hanging 的版本更新,透過認識 Puma 不同的重啟方式,以讓我們可以在不同的情境及條件下,選擇最為適合的方式來維護並營運自己的服務。
從上述不同的設定及描述中我們可得出,在大部分的情況下,由於 Phased-Restart 是逐一的重啟各個 Worker、重啟的過程之中其他 Worker 會繼續處理請求,因此可以達到 Zero Downtime 且 Zero Hanging 的版本更新。
但也因為是 Worker 的逐一重啟,過程中會有短暫新舊程式碼同時共存的情況,同時 Phased-Restart 也不會重新讀取 Puma Configuration,此時 Hot Reload 就是較適合的 Fallback。透過開啟額外的 Puma Socket 來接收請求,在重啟過程中請求仍可以被正常接收,待 Puma Service 重啟完成後在交由 Puma Service 處理,雖不能做到 Zero Hanging,但使用者的請求仍然可以被正確接收。
在要更新一些更為深層的設定,如綁定的 ListenStream、或是其他系統設置時,才不可避免的必須要使用到 Puma 的 Normal Restart。這種情況下若要達成 Zero Downtime,或許就得要使用 Infrastructure Level 的設計來做到 Zero Downtime 的需求了。
Referecnes
- Puma Official Documentation. Architecture. Retrieved July 21, 2019, from https://github.com/puma/puma/blob/master/docs/architecture.md
- Puma Official Documentation. Deployment engineering for puma. Retrieved July 21, 2019, from https://github.com/puma/puma/blob/master/docs/deployment.md
- Puma Official Documentation. Restarts. Retrieved July 21, 2019, from https://github.com/puma/puma/blob/master/docs/restart.md
- Puma Official Documentation. Systemd. Retrieved July 21, 2019, from https://github.com/puma/puma/blob/master/docs/systemd.md
- Heroku Dev Center Rails Support Documentation. Deploying Rails Applications with the Puma Web Server. Retrieved July 21, 2019, from https://devcenter.heroku.com/articles/deploying-rails-applications-with-the-puma-web-server
👩🏫 課務小幫手:
✨ 想掌握 Ruby on Rails 觀念和原理嗎?
我們有開設 🏓 Ruby on Rails 實戰課程 課程唷 ❤️️